
An example from the TransientTables
Abstract
Humans continuously make new discoveries, and understanding temporal sequence of events leading to these breakthroughs is essential for advancing science and society. This ability to reason over time allows us to identify future steps and understand the effects of financial and political decisions on our lives. However, large language models (LLMs) are typically trained on static datasets, limiting their ability to perform effective temporal reasoning.
To assess the temporal reasoning capabilities of LLMs, we present the TransientTables dataset, which comprises 3,971 questions derived from over 14,000 tables, spanning 1,238 entities across multiple time periods. We introduce a template-based question-generation pipeline that harnesses LLMs to refine both templates and questions. Additionally, we establish baseline results using state-of-the-art LLMs to create a benchmark. We also introduce novel modeling strategies centered around task decomposition, enhancing LLM performance.
Video
Dataset Creation
The TransientTables dataset was created using a combination of automated and manual processes. It includes a diverse set of tables spanning multiple domains and time periods, ensuring a comprehensive evaluation of temporal reasoning capabilities. The dataset generation pipeline leverages LLMs for template-based question generation and refinement.
Question Categorization
We categorized the questions in our dataset along several dimensions:
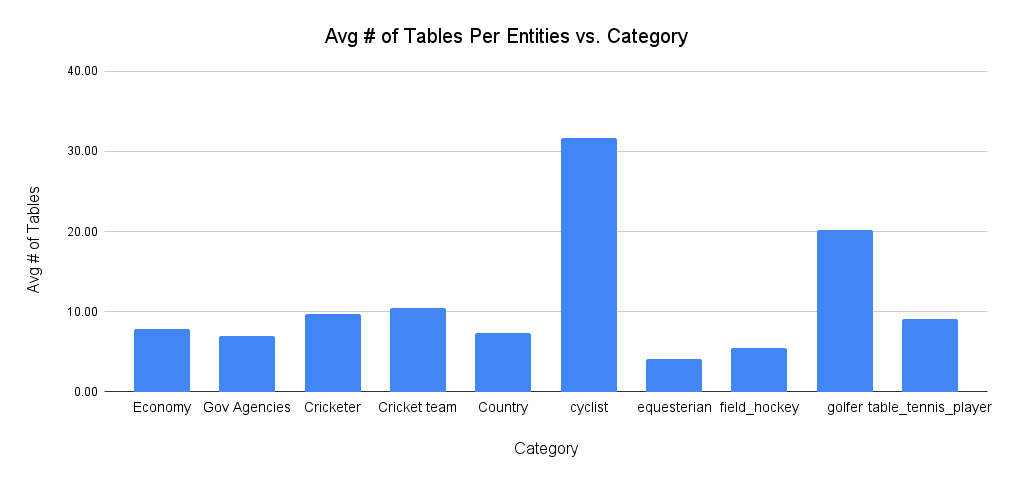
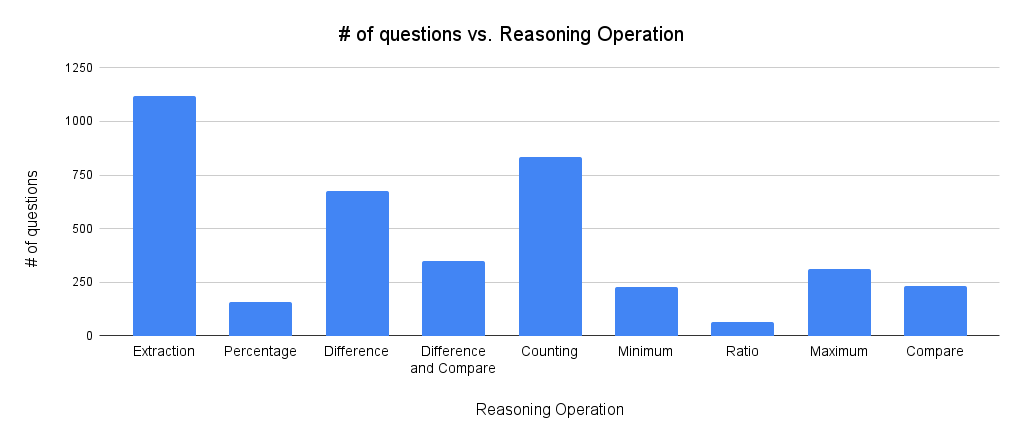
In terms of time information, 2,985 questions have implicit temporal references while 986 have explicit temporal references. We also classified questions by reasoning type, including extraction, counting, comparison, and others. Finally, we assessed complexity based on whether questions involved a single key (2,113 questions) or multiple keys (1,858 questions) across the timeline.
Modeling Techniques
For our evaluation approach, we explored several modeling techniques:
We varied the information granularity from the closed book (no tables provided) to a single table, full timeline, and Oracle timeline settings. This helped us understand the models' reliance on contextual information versus their pre-trained knowledge.
We also investigated four task decomposition approaches:
- Without Decomposition (WD): Direct answer generation
- Information Retrieval (IR): Table retrieval + Answer generation
- Information Extraction (IE): Key extraction + Answer generation
- Information Retrieval-Extraction (IRE): Table retrieval + Key extraction + Answer generation
Results
The following carousel showcases key plots from our results, highlighting the performance of various modeling techniques and insights derived from the dataset.